
Another bug from VMware/HPE – unfortunately we don’t have public KB available at this point. As per our conversation with VMware engineer this issue affects both ESXi 5.5 and ESXi 6.x hosts.
I suspect VMware sfcb service fails to clear temporary files or HPE CIM providers create files which they are not suppose to.
I observed this issue with HPE ProLiant BL660c Gen8 blades running ESXi 5.5. These blades come with 4 CPU sockets and 1TB of ram – they are hosting VDI environment so they do have high density and a lot of power on/off operations.
As the troubleshooting options we tried updating to the latest ESXi patches, HPE drivers and software but issue was still persisting.
Scope
Issue affects ESXi 5.5 and ESXi 6.x running HPE CIM providers, such as OEM HPE customized images.
Symtomps
Unable to power on new VMs, vMotion fails.
vkernel.log shows the following errors:
Cannot create file /var/run/sfcb/52494bef-1566-c7e5-6604-676ddd5b9c46 for process sfcb-CIMXML-Pro because the inode table of its ramdisk (root) is full.
You see alot of files inside /var/run/sfcb directory
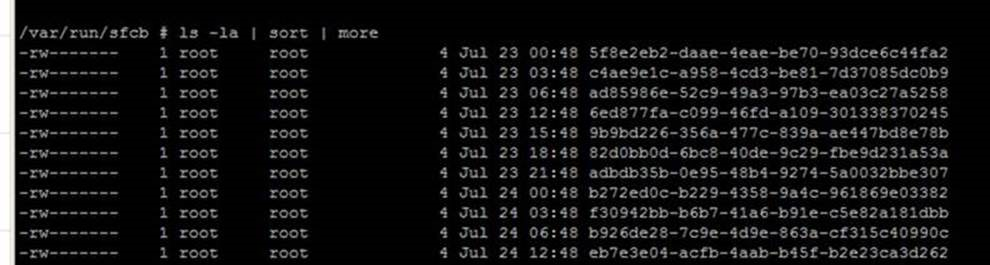

Below you will find workarounds to address this issue.
Temporary workaround
1. Disable HA on the cluster to avoid alerts.
2. Stop SFCB by running the following command:
/etc/init.d/sfcbd-watchdog stop
3. Delete files inside /var/run/sfcb
If you get error -sh: can't fork delete files in small batches with commands such as rm [0-2]* or even more granual with rm abcd*
![]()
4. Start SFCB by running the following command:
/etc/init.d/sfcbd-watchdog start
5. Verify fs for free ionodes:
esxcli system visorfs ramdisk list
6. Restart management agents
/etc/init.d/hostd restart
/etc/init.d/vpxa restart
At this point host will temporary disconnect from vCenter, so don’t panic as all VMs are still online.
Permanent workaround
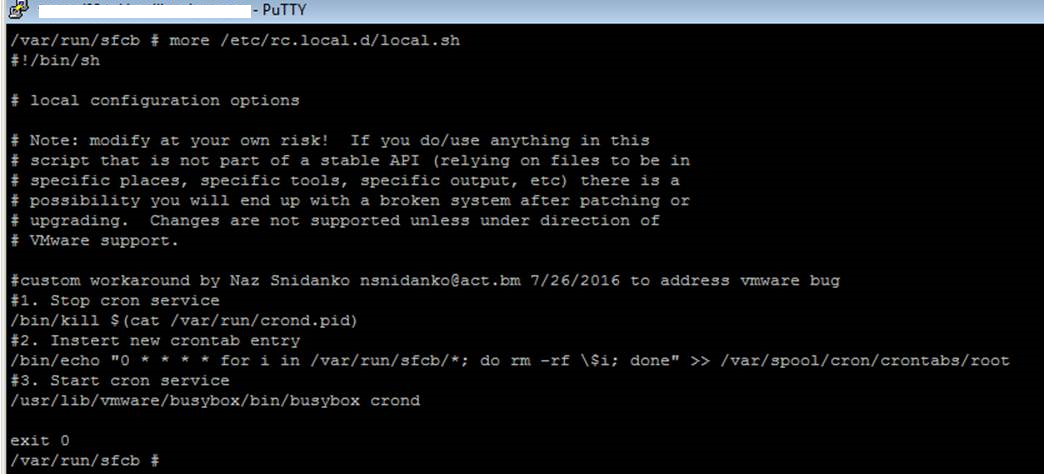
Now to address this issue permanently i suggest implementing cron job, which clears files every hour from /var/run/sfcb directory. Make sure to clear all files prior using instructions above prior to proceeding with this. Now onto our permanent solution – SSH into the host and edit vi /etc/rc.local.d/local.sh file. Copy and paste the following above exit 0
#custom workaround by Naz Snidanko nsnidanko@act.bm 7/26/2016 to address vmware bug
#1. Stop cron service
/bin/kill $(cat /var/run/crond.pid)
#2. Instert new crontab entry
/bin/echo "0 * * * * for i in /var/run/sfcb/*; do rm -rf \$i; done" >> /var/spool/cron/crontabs/root
#3. Start cron service
/usr/lib/vmware/busybox/bin/busybox crond
That’s it.